Bazy danych

1.Definicja: Bazy danych to dziedzina informatyki, dynamicznie się rozwijająca i mająca szerokie zastosowanie w wielu miejscach wszędzie tam, gdzie niezbędne jest przetwarzanie jakichkolwiek danych. Rzadko spotykanym bowiem zjawiskiem jest aplikacja, która nie operuje na żadnych danych, a bazy niezwykle ułatwiają pracę z nimi. Zwykły użytkownik komputera, a nawet osoba, która z niego nie korzysta, spotyka się z bazami danych na każdym kroku. Czytelnik korzysta właśnie z serwisu, który nie istniałby bez bazy danych. Kupno biletu kolejowego, robienie zakupów czy nawet zwykłe wykonanie połączenia telefonicznego to czynności, które zazwyczaj nie kojarzą się z informatyką i z jej omawianym działem, a jednak korzystają z jego wytworów i mają z nim bardzo wiele wspólnego. Można zaryzykować stwierdzenie, że wiele innych dziedzin zarówno informatyki, jak i życia nie rozwijałoby się lub ich rozwój byłby ograniczony, gdyby nie istniały bazy danych. Problem przetwarzania informacji przez aplikacje istniał od początku istnienia programowania, a upływ czasu spowodował powstanie baz danych oraz systemów zarządzania bazami danych (silnikami baz danych). Jakiekolwiek operowanie na większych ilościach informacji implikuje bowiem rozwój tego działu informatyki.
Zwroty "operowanie na danych", "większe ilości informacji" jest oczywiście nieprecyzyjny, a np. "silnik bazy danych" może być kompletnie niezrozumiały. Warto byłoby z początku sprecyzować zatem, co one (oraz inne im podobne) oznaczają, a w późniejszym czasie sformalizować w pewien sposób obszar, w jakim się poruszamy. Skomputeryzowana baza danych umożliwia przechowywanie obiektów. Jedna baza danych może zawierać wiele tabel, na przykład system śledzenia inwentarza korzystający z trzech tabel nie stanowi trzech baz danych, ale jedną — zawierającą trzy tabele. Jeśli baza danych programu Access nie jest zaprojektowana z myślą o używaniu danych lub kodu z innego źródła, jej tabele są przechowywane w jednym pliku wraz z pozostałymi obiektami, takimi jak formularze, raporty, makra i moduły. Bazy danych utworzone w formacie programu Access 2007 mają rozszerzenie pliku accdb, natomiast bazy danych utworzone w formacie wcześniejszych wersji programu Access mają rozszerzenie pliku mdb. Program Access 2007 umożliwia tworzenie plików we wcześniejszych formatach (na przykład format programu Access 2000 i format programów Access 2002–2003).
Program Access pozwala wykonywać następujące czynności:
Dodawanie nowych danych, takich jak nowy element inwentarza, do bazy danych
Edytowanie istniejących danych w bazie danych, na przykład zmienianie bieżącej lokalizacji elementu
Usuwanie informacji, na przykład po sprzedaniu elementu lub wycofaniu go ze sprzedaży
Organizowanie i przeglądanie danych na różne sposoby
Udostępnianie danych innym osobom za pomocą raportów, wiadomości e-mail, sieci intranet lub Internet
2.Przykładowe zastosowanie 3D
Programy które są wykorzystywane do projektowania, wizualizacji i wyceny wnętrz. W programach np. CAD Kuchnie, CAD Decor i CAD Decor PRO można dodawać modele 3D do bazy użytkownika, przy pomocy Konwertera 3D, importując je z innych programów np. 3D Studio czy AutoCAD lub samodzielnie tworząc je w naszym oprogramowaniu. Elementy z baz można wstawiać do projektu, modyfikować ich wymiary, edytować kolor, fakturę i inne właściwości. Wstawione modele zostają automatycznie uwzględnione w wycenie.
3.Typy BD
-kartotekowe
baza danych złożona z jednej tablicy, która zawiera identyczną strukturę pól. Każda tablica danych jest samodzielnym dokumentem i nie może współpracować z innymi tablicami, w przeciwieństwie do relacyjnej bazy danych.
Przykładami kartotekowej bazy danych są spisy danych osobowych czy spisy książek lub płyt. Poniższa baza składa się z jednej tabeli zawierającej 3 rekordy, z których każdy ma 4 pola.
| Nazwisko | Imię | Miasto | E-mail |
|---|
| Kowalski | Jan | Warszawa | kowalski@warszawa.pl |
| Wiszniewska | Anna | Kraków | wiszniewska@krakow.pl |
| Zieliński | Henryk | Wrocław | zielinski@wroclaw.pl |
Dane w kartotekowych bazach danych można sortować, przeszukiwać, stosować w nich filtry ograniczające zakres wyświetlanych informacji.
Kartotekowe bazy danych można tworzyć w dowolnym programie zarządzającym bazami danych czy w arkuszach kalkulacyjnych, a nawet w prostych edytorach tekstów (pliki z wartościami oddzielanymi przecinkami - CSV, lub tabulatorami - TSV). Specjalne programy do tworzenia tego rodzaju baz są też dołączane do pakietów zintegrowanych, jakMicrosoft Works. Użytkownik może w nich utworzyć nie tylko samą bazę, czyli tabele z danymi, ale i graficzny interfejs użytkownika, definiując położenie pól i dołączając rozmaite elementy uboczne powtarzające się przy przeglądaniu rekordów, jak np. grafikę.
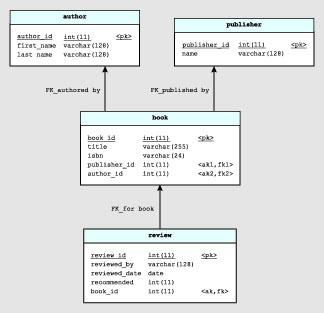
-relacyjne
baza danych, w której dane są przedstawione w postaci relacyjnej.
W najprostszym ujęciu w modelu relacyjnym dane grupowane są w relacje, które reprezentowane są przez tablice. Relacje są pewnym zbiorem rekordów o identycznej strukturze wewnętrznie powiązanych za pomocą związków zachodzących pomiędzy danymi. Relacje zgrupowane są w tzw. schematy bazy danych. Relacją może być tabela zawierająca dane teleadresowe pracowników, zaś schemat może zawierać wszystkie dane dotyczące firmy. Takie podejście w porównaniu do innych modeli danych ułatwia wprowadzanie zmian, zmniejsza możliwość pomyłek, ale dzieje się to kosztem wydajności.

4. Struktura bazy danych
-rekord (pojedynczy wpis)
Rekord (ang.record) – zwany także krotką lub wierszem, to pozioma struktura danych opisująca jeden obiekt. Rekord składa się z pól opisujących dokładnie cechy obiektu np. pojedynczego pracownika.
-pole rekordu
Pole (ang. field) – zwane także atrybutem lub kolumną, to struktura danych opisująca pojedynczą daną w rekordzie np. nazwisko pracownika
-klucze
Klucz podstawowy (ang. primary key) zwany też kluczem głównym to jedno lub więcej pól, których wartość jednoznacznie identyfikuje każdy rekord w tabeli. Taka cecha klucza nazywana jest unikatowością. Klucz podstawowy służy do powiązania rekordów w jednej tabeli z rekordami z innej tabeli. Klucz podstawowy jest nazywany kluczem obcym, jeśli odwołuje się do innej tabeli. Na przykład, w bazie pracowników kluczem podstawowym może być numer ewidencyjny pracownika.
Klucz podstawowy jednopolowy (ang. single primary key)Jeśli istnieje pole zawierające dane unikatowe, jak na przykład numer katalogowy czy numer identyfikacyjny, można je zadeklarować jako klucz podstawowy. Jeśli jednak w polu tym powtarzają się wartości, klucz podstawowy nie zostanie ustawiony. Aby znaleźć rekordy zawierające te same dane, należy usunąć rekordy o powtarzających się wartościach bądź zdefiniować wielopolowy klucz. podstawowy.
Klucz podstawowy wielopolowy zwany też kluczem złożonym (ang.composed key)
W sytuacji, gdy żadne z pól nie gwarantuje unikatowości wartości w nim zawartych, należy rozważyć możliwość utworzenia klucza podstawowego złożonego z kilku pól.


5. Obsługa bazy danych
-kwerendy (zapytania)
Kwerendy stanowią podstawowe narzędzie baz danych, które może spełniać wiele różnych funkcji. Najczęściej są one używane do pobierania określonych danych z tabel. Często dane, które mają być pobrane, znajdują się w kilku tabelach — kwerendy pozwalają przeglądać takie dane w jednym arkuszu danych. Poza tym nie zawsze jest konieczne wyświetlanie wszystkich rekordów, dlatego przy użyciu kwerend można określać odpowiednie kryteria „filtrowania” danych, aby uzyskać dostęp tylko do potrzebnych rekordów. Kolejnym zastosowaniem kwerend jest dostarczanie danych dla formularzy i raportów.
Niektóre kwerendy umożliwiają edytowanie danych w tabelach źródłowych za pomocą arkusza danych kwerendy. W przypadku używania kwerend aktualizujących należy pamiętać, że zmiany zostaną wprowadzone w tabelach, a nie tylko w arkuszu danych kwerendy.
Istnieją dwa podstawowe typy kwerend: kwerendy wybierające i kwerendy funkcjonalne. Kwerenda wybierająca pobiera dane i udostępnia je. Można wyświetlić wyniki takiej kwerendy na ekranie, wydrukować je lub skopiować do schowka. Wyniki kwerendy mogą też posłużyć jako źródło rekordów dla formularza lub raportu.
Kwerenda funkcjonalna, jak wskazuje jej nazwa, służy do wykonywania zadań związanych z danymi. Kwerendy funkcjonalne umożliwiają tworzenie nowych tabel, dodawanie danych do istniejących tabel oraz aktualizowanie i usuwanie danych.
-formularze
Formularze są też określane jako „ekrany wprowadzania danych”. Stanowią one interfejs do pracy z danymi i często zawierają przyciski umożliwiające wykonywanie różnych poleceń. Można utworzyć bazę danych bez korzystania z formularzy, edytując dane w arkuszach danych tabel. Większość użytkowników baz danych woli jednak używać formularzy do przeglądania, wprowadzania i edytowania danych przechowywanych w tabelach.
Formularze usprawniają pracę z danymi, udostępniając łatwy w użyciu interfejs, a także umożliwiając dodawanie elementów funkcjonalnych, takich jak przyciski poleceń. Po odpowiednim zaprogramowaniu przyciski umożliwiają określanie danych wyświetlanych w formularzu, otwieranie innych formularzy lub raportów oraz wykonywanie wielu innych zadań. Przykładem może być formularz o nazwie „Formularz klienta” służący do pracy z danymi klienta. Taki formularz może zawierać przycisk otwierający formularz zamówienia, który pozwala wprowadzić nowe zamówienie dla danego klienta.
Dzięki formularzom można określać sposoby interakcji użytkowników z danymi zawartymi w bazie danych. Można na przykład utworzyć formularz wyświetlający tylko wybrane pola i udostępniający tylko określone operacje. Ułatwia to ochronę i poprawne wprowadzanie danych.
-raporty
Raporty służą do podsumowywania i wyświetlania danych zawartych w tabelach. Zazwyczaj raport umożliwia odpowiedź na określone pytanie dotyczące danych, na przykład „Ile pieniędzy otrzymaliśmy od poszczególnych klientów w tym roku?” lub „W jakich miastach mają swoje siedziby nasi klienci?” Każdy raport można sformatować w sposób zwiększający czytelność danych.
Raport można uruchomić w dowolnym momencie, przy czym zawsze będzie on odzwierciedlał bieżące dane znajdujące się w bazie danych. Raporty są zazwyczaj formatowane z myślą o ich drukowaniu, ale można też wyświetlać je na ekranie, eksportować do innych programów lub wysyłać jako wiadomości e-mail.